I have been working on membership proofs (One-out-of-Many, Lelantus, Tiptych, Arcturus, etc) and have come up with an optimization that greatly improves batch verification performance in any membership proof derived from Groth & Kohlweiss’s One-out-of-Many proof scheme.
I have an early paper (very early, still missing benchmarks and concrete numbers) describing the improvement here:
I have a benchmark demonstrating 60% verification speedup for a batch of 100 proofs with set size of 4096:
I think this optimization could be very useful to Lelantus, so I wanted to share. I welcome any feedback/comments/criticisms. Feel free to create an issue or PR on Github. I will check this forum occasionally, but it will be quicker to reach me via email (see any Cargo.toml file on my github) or via GitHub issue/PR.
I still need to finish up the paper, as well as add sample code and build out more benchmarks. Please treat this paper/github as early proof of concept only.
Hey @cargodog! Thanks for dropping by! Yes I saw this on Justin’s tweet and got really excited so had shared it with Aram beforehand who also thinks it is a very interesting technique and there is a possible good performance gain here. Sarang also reached out to us also on this a couple of days ago.
As Zcoin uses much larger sets (65k), this would be very significant.
We were planning to dive deeper into it once we finished launching Lelantus’ testnet. We’ll be glad to provide feedback.
Hey @cargodog. Thanks for the heads up and congrats on this great finding. It definitely will be super useful and we will keep you posted upon our progress on the implementation.
@cargodog I have skimmed the paper today. Thanks for the thorough elaboration of the ideas. We will start prototyping this after finishing the testnet release first. Meantime, what are your thoughts on Beam’s ideas of optimized computations of these exponent values?
Thanks for sharing! I was not aware of Beam’s work, but I am glad to know it now.
After looking at Beam’s approach, I agree their optimization appears to be more computationally efficient. That is an elegant solution, which is likely preferable to the original One-out-of-many construction, as well as my iterative approach over Gray coded construction.
It would be marginally more efficient and simpler to implement their recursive computation over a Gray coded set, however the performance gain would be minor compared to the performance gain they’ve already achieved.
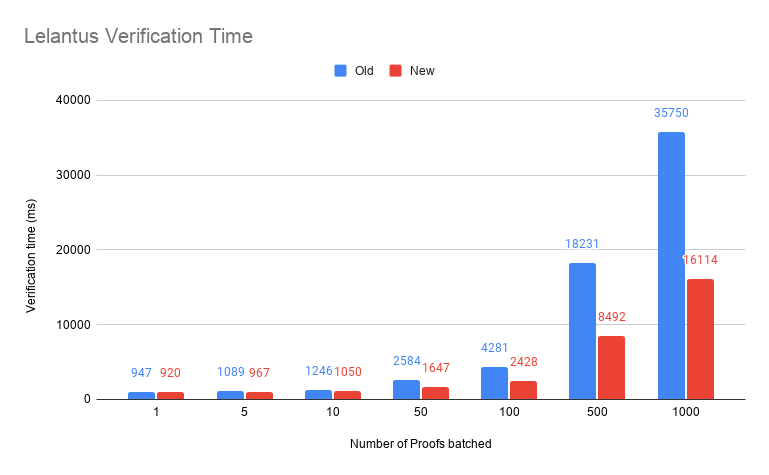
Using this optimization we managed to bring verification numbers significantly
N = 65536 n = 16 m = 4 M = 1 Verify time new 920 old 947 ms
N = 65536 n = 16 m = 4 M = 5 Verify time new 967 old 1089 ms
N = 65536 n = 16 m = 4 M = 10 Verify time new 1050 old 1246 ms
N = 65536 n = 16 m = 4 M = 50 Verify time new 1647 old 2584 ms
N = 65536 n = 16 m = 4 M = 100 Verify time new 2428 old 4281 ms
N = 65536 n = 16 m = 4 M = 500 Verify time new 8492 old 18231 ms
N = 65536 n = 16 m = 4 M = 1000 Verify time new 16114 old 35750 ms
This was using Beam’s approach which required very little changes. Cargodog’s optimization as he mentioned might yield a bit more but would require more code changes.